Service Solution

Project Title: Server Failure Prediction System
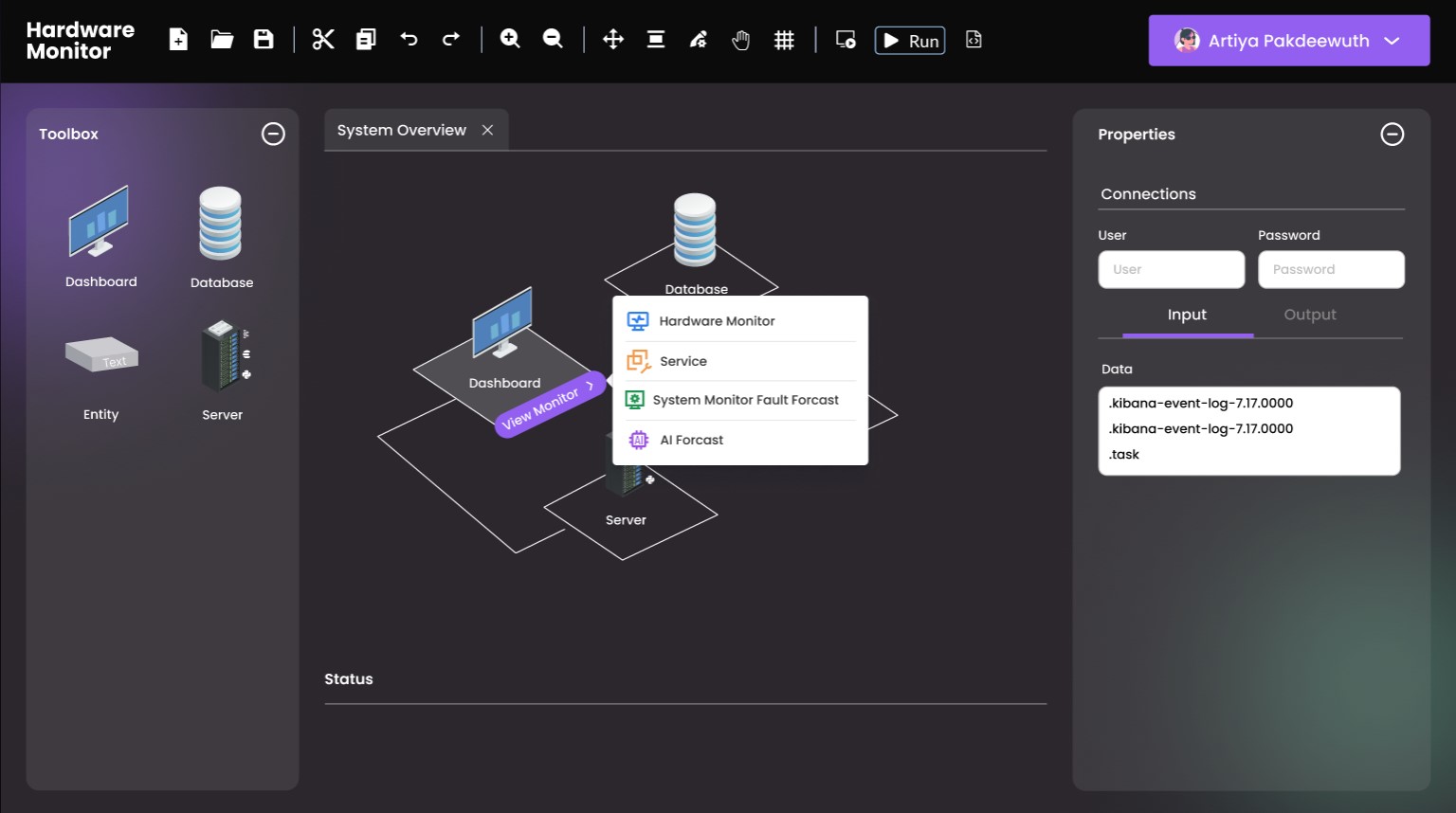
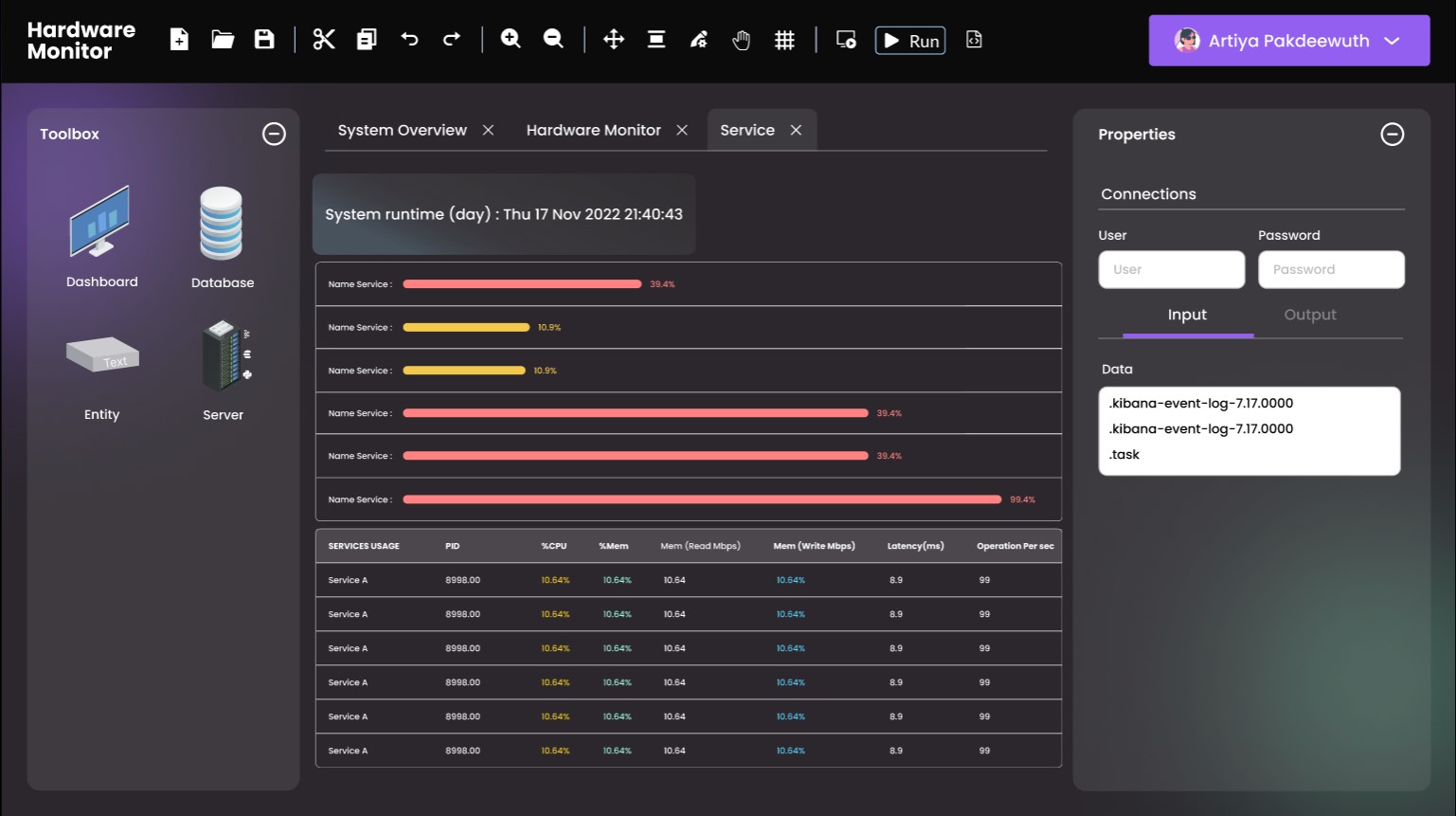
This project aims to develop a system capable of detecting and alerting on abnormal changes in various system metrics. The system is designed to operate in diverse environments such as public, hybrid, private, cloud-native, and on-premise. By analyzing logs and correlating events across applications, the system can quickly identify the root cause of issues, enabling efficient troubleshooting. The project leverages Machine Learning to predict anomalies and automatically refine models based on new data. This allows the system to continuously learn and improve its detection and alerting capabilities. The success of this project not only signifies technological advancements in server management but also contributes to international research, as evidenced by its publication in the ICSEng 2022 journal in Japan, highlighting the value of developing efficient systems and delivering high-quality customer service.
ภาพรวมโครงการ
โครงการระบบพยากรณ์การล้มเหลวของเซิร์ฟเวอร์ มีวัตถุประสงค์เพื่อพัฒนาระบบที่สามารถตรวจจับและแจ้งเตือนเมื่อมีการเปลี่ยนแปลงผิดปกติในปริมาณรายการของระบบต่าง ๆ โดยระบบนี้ออกแบบมาให้สามารถทำงานได้ในหลายสภาพแวดล้อมไม่ว่าจะเป็น public cloud, hybrid cloud, private cloud, cloud native หรือ on-premise นอกจากนี้ยังสนับสนุนฟีเจอร์ที่ช่วยให้การวิเคราะห์ปัญหาทางเทคนิคเกิดขึ้นได้อย่างรวดเร็วยิ่งขึ้น โดยอิงจากการเรียนรู้จากข้อมูลใน log ซึ่งจะช่วยค้นหา root cause ของปัญหาได้อย่างแม่นยำและมีประสิทธิภาพ
ขอบเขตงาน:
การตรวจจับและแจ้งเตือน: ระบบสามารถตรวจจับและแจ้งเตือนเมื่อมีความผิดปกติในปริมาณรายการที่เกิดขึ้น โดยสามารถปรับเปลี่ยนค่าการแจ้งเตือนได้ทั้งแบบ manual และ auto
การจัดการ Threshold: ผู้ใช้สามารถตั้งค่า thresholds เพื่อการแจ้งเตือนที่เหมาะสมตามสถานการณ์ในระบบ
การ Trigger Script/Command: สามารถกำหนด Rule เพื่อ Trigger สคริปต์เมื่อพบปัญหาที่เกินเกณฑ์ที่ตั้งไว้ เช่น Timeout สูง
การทำ Event/Log Correlation: รองรับการทำ Event/Log Correlation ข้ามแอปพลิเคชันเพื่อการวิเคราะห์และพยากรณ์ปัญหาล่วงหน้า
การวิเคราะห์ทั้ง Transaction และ Data Warehouse: ระบบสามารถวิเคราะห์ข้อมูล transaction และเชื่อมโยงข้อมูลจากหลายระบบเพื่อตรวจสอบประสิทธิภาพและต้นเหตุของปัญหาอย่างมีประสิทธิภาพ
การปรับปรุง Model อัตโนมัติ: ระบบจะมีการปรับปรุงโมเดลแบบอัตโนมัติเพื่อปรับให้เข้ากับข้อมูลใหม่ ๆ อยู่เสมอ
ความสำเร็จของโครงการ:
โครงการนี้ประสบความสำเร็จในการพัฒนาระบบที่สามารถตรวจจับและแจ้งเตือนการทำงานผิดปกติได้อย่างมีประสิทธิภาพ ระบบสามารถทำงานได้อย่างยืดหยุ่นและรองรับการวิเคราะห์ข้อมูลแบบเรียลไทม์ รวมถึงการเรียนรู้จากการใช้งานที่ผ่านมาเพื่อนำมาปรับปรุงการแจ้งเตือนในอนาคต ทั้งนี้ยังสามารถปรับตัวและส่งเสริมความสามารถในการพยากรณ์ที่มีคุณค่าเมื่อระบบประสบปัญหา ทำให้การดำเนินการยังสามารถเป็นไปอย่างราบรื่น
โครงการนี้ไม่เพียงแต่สนับสนุนการตรวจสอบปัญหาล่วงหน้า แต่ยังเปิดทางให้การวิจัยเกี่ยวกับระบบนี้ได้รับการตีพิมพ์ในวารสารวิชาการระดับนานาชาติ ICSEng 2022 ที่โตเกียว ประเทศญี่ปุ่น ซึ่งแสดงให้เห็นถึงความสำคัญและคุณค่าของการพัฒนาระบบที่บูรณาการเทคโนโลยี Machine Learning ในการป้องกันปัญหาล่วงหน้าในระดับองค์กร สำหรับรายละเอียดเพิ่มเติมเกี่ยวกับงานวิจัย สามารถศึกษาได้จากลิงก์:
ML-Based System Failure Prediction Using Resource Utilization
กลับไปหน้า Data Analytic &AI/ML Service Solution